Hi @drllau_LexDAO,
Our Data Team produced further analysis specifically regarding point (a):
We’ve successfully developed a preliminary predictive model leveraging historical incentive campaign data. Although still limited by the available dataset, early results demonstrate a promising ability to estimate the likelihood of success of individual incentive campaigns. With additional data, we expect the accuracy and usefulness of this predictive capability to improve significantly.
In conclusion, this proof-of-concept highlights clear opportunities to leverage existing incentive data to better inform future decisions for Uniswap’s incentive strategies. Should the DAO find value in exploring this further, we’re open to discussing how we might support the community in enhancing these predictive insights, potentially as part of future analytics engagements.
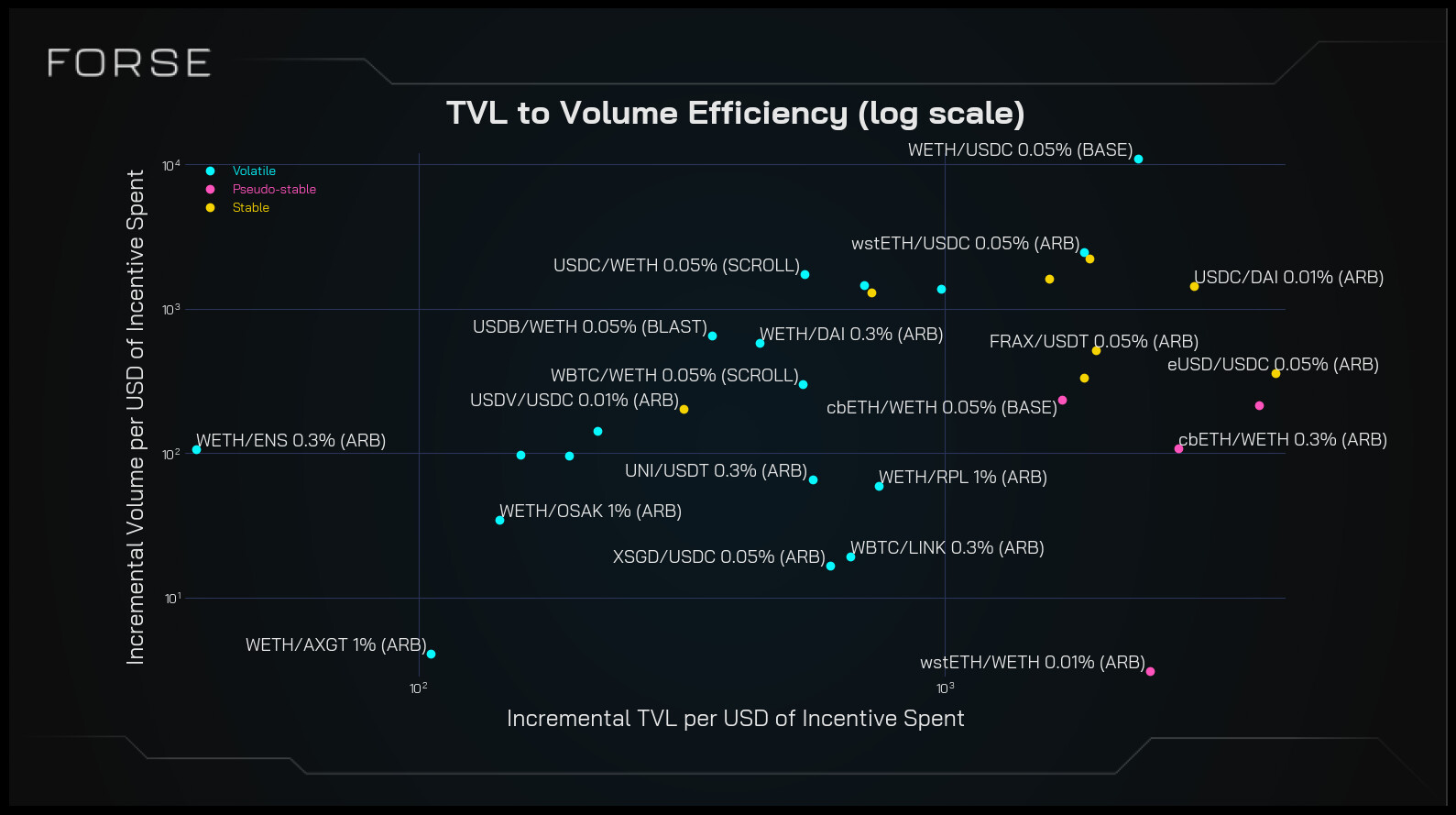
Regarding (b), as mentioned earlier, you can already review migration trends directly in the newly released terminal on the Forse Platform.
As for (c), our opinion remains the same—while adjusting for macroeconomic factors such as CPI or total crypto market cap is feasible, current data limitations—specially in newer chains—mean these adjustments would likely provide limited insights at this time.
Thanks again for your questions, and let us know if there’s anything else we can clarify!
Analysis
This doc presents the results of a proof of concept run by Forse to predict the performance of incentivization campaigns on Uniswap pools. Our goal was to identify patterns in the pre-campaign data of liquidity pools that could help predict the effectiveness of launching an incentivization campaign on those pools.
We created a model that predicts the likelihood of success for incentivization campaigns on a per-pool basis, using Machine Learning.
We assess the success of a campaign by measuring the post-campaign TVL compared to pre-campaign: if the TVL growth of an incentivized pool significantly outpaces the TVL growth of the Uniswap protocol, we consider the campaign as successful.
The amount of training data used is very limited, the model would require additional training inputs to guarantee high accuracy and performance. Nevertheless, this proof-of-concept demonstrates that there are opportunities to leverage existing campaign data to increase the success of future UNI campaigns.
Post-campaign TVL split by model predictions
By comparing the pool-by-pool TVL change after the campaign vs before the campaign, we can see that although some top performers are missed, it performs well to anticipate which pools will yield good post-campaign results.